Hurtig definition
Dynamiske sitemaps er sitemaps, der opdateres automatisk. Disse sitemaps formateres oftest i XML-format – det er denne type sitemaps, man indsender til Googles Search Console for at gøre opmærksom på de sider, der er tilgængelige på ens website.
Sådan fungerer XML Sitemaps
Googlebot finder og indekserer sider igennem crawl af links. Når den indekserer en webside, følger den alle links, der måtte være på en side og går fra den ene side til den anden. Linkes der ikke til en side, vil Googlebot ikke blive præsenteret for siden og vil derfor ikke indeksere den.
Er der indsendt et dynamisk sitemap, vil Google følge dette sitemap, uagtet om der er interne links til de sider, der er listet i sitemappet. Indsender man et sitemap, opfordrer man meget kraftigt Google til at tage stilling til de sider, der indsendes, og Google vil se nærmere på dem, så længe siderne er i sitemappet.
Vigtigt: Det kan føre til, at sider, der ikke skulle indekseres, bliver det. Det kan også skabe orphan pages, som i realiteten ingen jordisk chance vil have for at rangere.
Det er derfor helt essentielt
Det er derfor helt essentielt, at dit XML-sitemap er 100% retvisende. Er det ikke det, er det bedre ikke at benytte sig af et XML-sitemap.
🚫 Bedre ingen sitemap end en forkert sitemap der kan skade din SEO.
Hvad skal et XML-sitemap indeholde?
Et XML-sitemap skal indeholde et link til hver eneste side på websitet, som er kompatibel (indekserbar). Et XML-sitemap må IKKE indeholde ikke-kompatible URL's.
✅ Inkludér disse:
- • Alle indekserbare sider
- • Sider med status 200 OK
- • Canoniske versioner af sider
- • Vigtige landing pages
- • Regelmæssigt opdateret indhold
❌ Ekskludér disse:
- • Sider med canonical til andre sider
- • Sider blokeret i robots.txt
- • Sider med noindex tag
- • Sorteringssider med filtre
- • 4xx fejlsider
Eksempel: Sider, der eksempelvis har et canonical-tag til en anden side end sig selv, aldrig bør være at finde i et sitemap, for der er ingen grund til, vi beder Googlebot tage stilling til den pågældende side.
Sådan finder du fejl i Google Search Console
Det er heldigvis nemt at finde frem til fejl og mangler i ens sitemap, hvis man har indsendt det til Google Search Console og har en aktiv konto.
Step-by-step guide:
- Åbn din Search Console-konto og log ind
- Klik på 'Dækning' i menuen
- Klik på 'Alle kendte sider' øverst i venstre hjørne
- Vælg 'Alle indsendte sider' i stedet
- Tjek for 'Ekskluderet' sider
Typiske problemer: En eksklusion kan have mange årsager, fx en side, der er crawlet, men endnu ikke indekseret. Men ofte vil der være tale om ikke-kompatible URL's, man har glemt at fjerne fra sit sitemap.
Eksempler fra Google Search Console
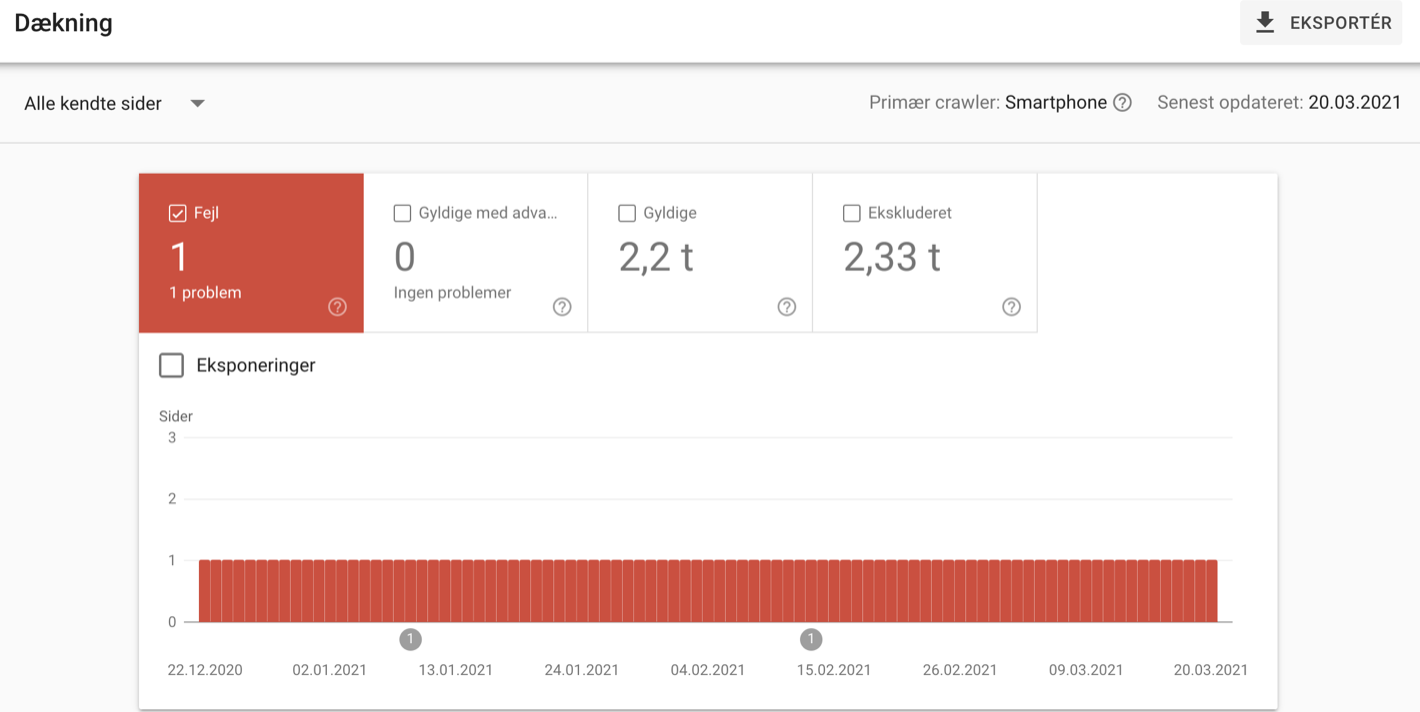
Eksempel på Search Console dækning med gyldige og ekskluderede sider
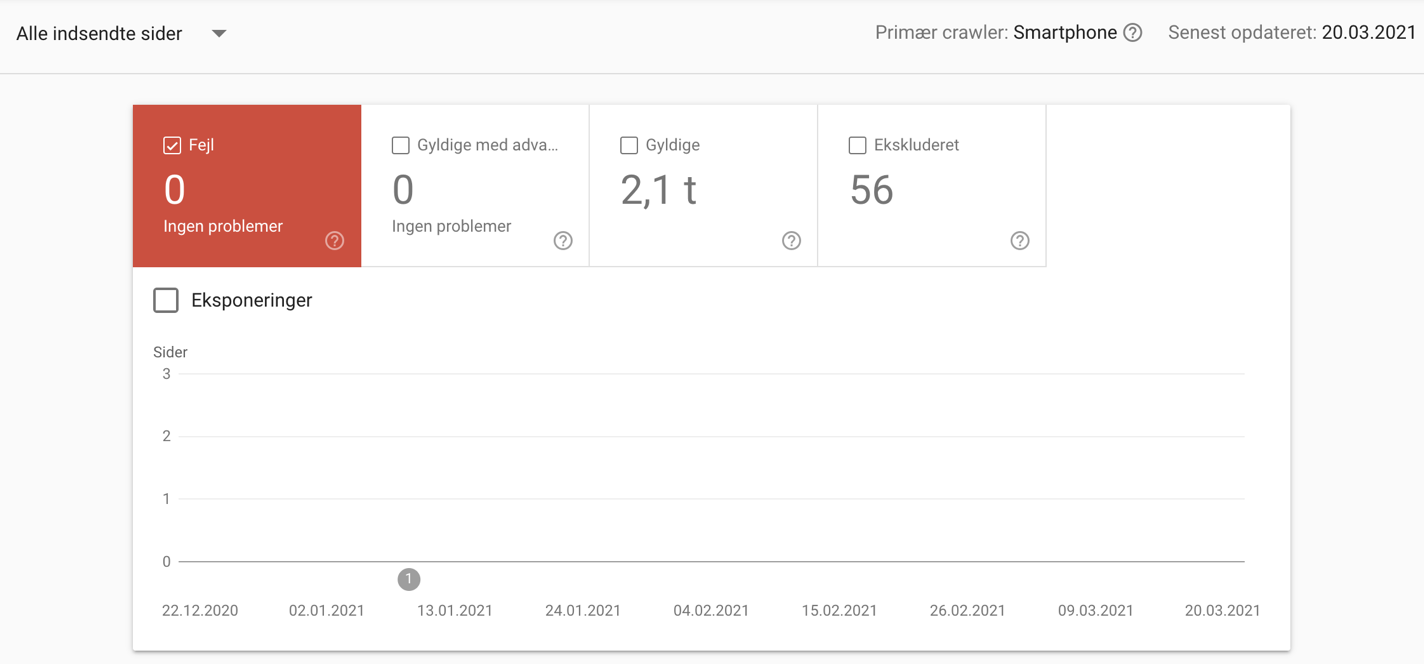
Sådan ser det ud når du filtrerer til kun indsendte sider fra dit sitemap
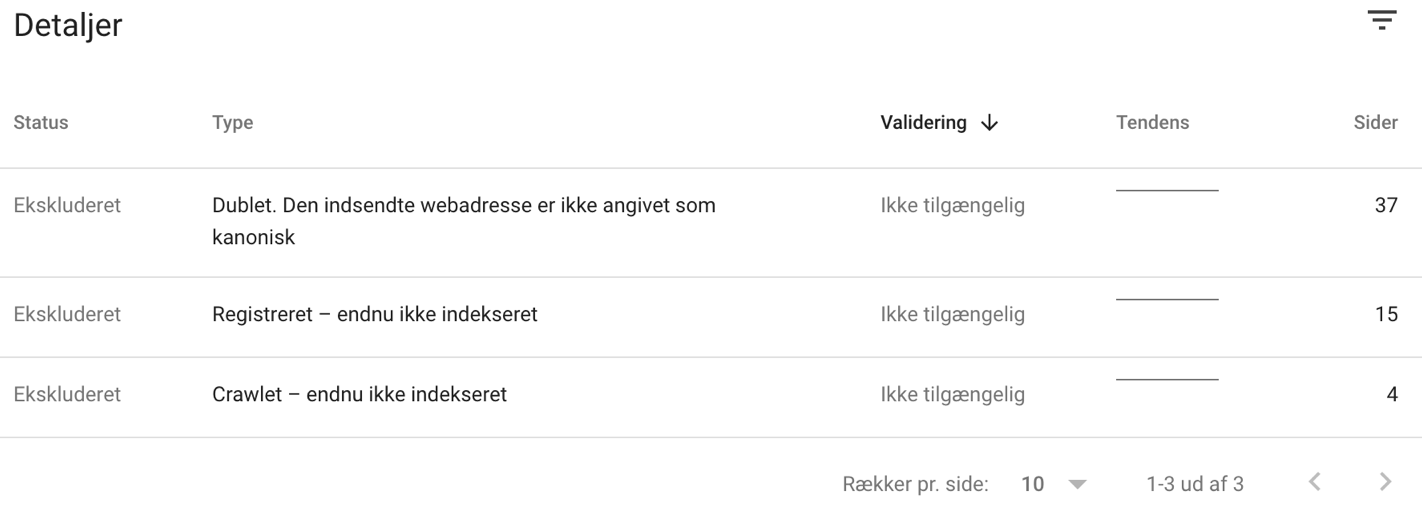
Detaljeret oversigt over problemer med dit sitemap inkl. dubletter og canonical issues
Typiske sitemap problemer
Dubletter
Den indsendte webadresse er ikke angivet som kanonisk. Alle URL's i denne liste peger på en anden adresse end sig selv som værende den kanoniske version.
4xx Fejlsider
Henviser du til 4xx-sider, vil de blive ved med at være en udfordring, fordi du stadig henviser til dem igennem dit sitemap – også selvom du ikke linker til dem på dit website.
Crawl Budget
Du har kun en vis mængde crawlbudget til rådighed, for hvert crawl du får foretaget – derfor vil du ikke spilde budgettet på ikke-kompatible sider.
Problemer med dit XML sitemap?
Korrekte XML sitemaps er kritiske for god indeksering. Få professionel hjælp til at optimere dit sitemap og finde fejl.